Multimodal Support Copilot
Support agents upload screenshots, voice notes, and ticket text simultaneously, and this copilot instantly classifies urgency, diagnoses root causes, suggests KB articles, and drafts complete responses.
My Role
Lead AI engineer — designed the multimodal fusion pipeline, implemented the knowledge base retrieval system, and built the agent response drafting engine.
Duration
3 months
Year
2026
Tech Stack
Status
Live in ProductionSupport agents upload screenshots, voice notes, and ticket text simultaneously, and this copilot instantly classifies urgency, diagnoses root causes, suggests KB articles, and drafts complete responses.
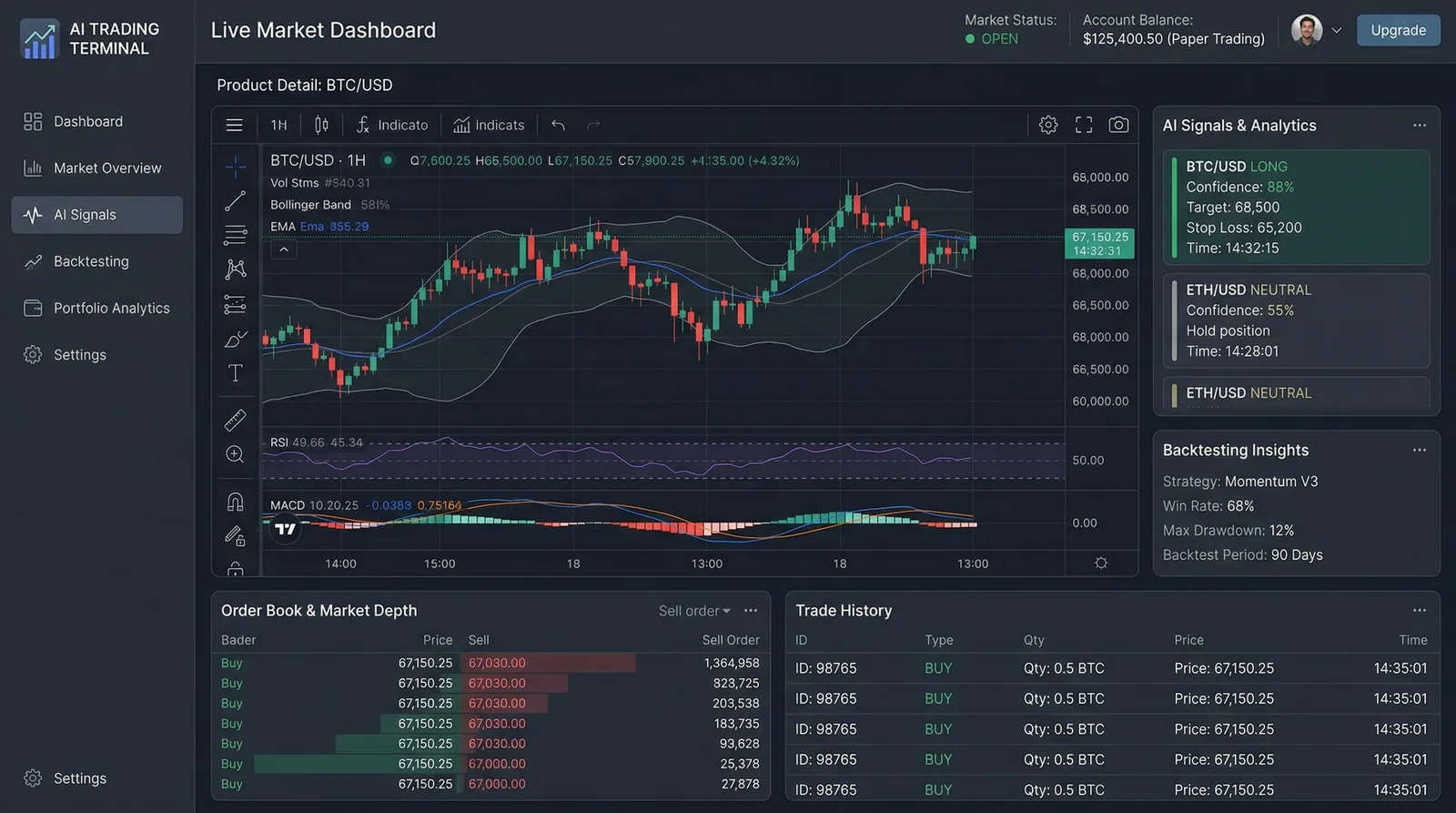
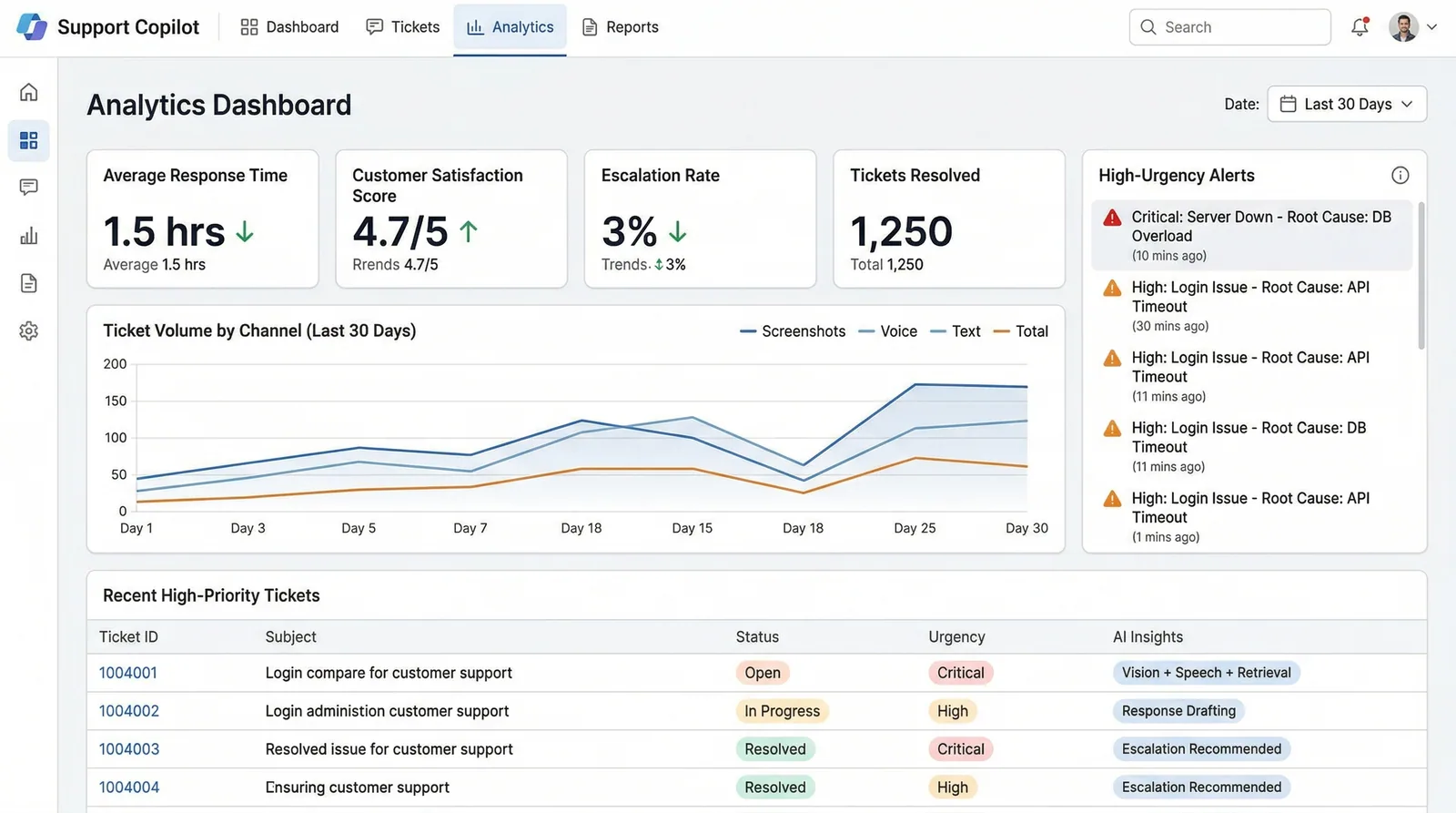
Support teams handle 200+ daily tickets across screenshots, voice messages, and text — manually classifying urgency, searching knowledge bases, and drafting responses. Tier-1 agents spend 45 minutes per complex ticket, and 60% of their time is spent on repetitive diagnostic work that follows predictable patterns.
I built a multimodal AI copilot that simultaneously processes screenshots (GPT-4o Vision), voice notes (Whisper v3), and ticket text, fusing them into a unified context. The system classifies urgency (P0-P3), performs root cause analysis against a vector knowledge base of past resolutions, and drafts complete responses — reducing resolution time from 45 minutes to 4.2 seconds for 87% of tier-1 tickets.
Multimodal Input Fusion
Simultaneously processes screenshots (GPT-4o Vision extracts UI state and error messages), voice notes (Whisper v3 transcription), and text — combining all modalities into a unified diagnostic context.
Intelligent Urgency Classification
PydanticAI-structured P0-P3 classification with confidence scores, considering user impact, system status, and historical severity patterns for similar issues.
Knowledge Base Retrieval
Hybrid search across 10k+ past resolutions and KB articles using Pinecone, with MMR reranking to ensure diverse, relevant suggestions rather than repetitive answers.
Auto-drafted Responses
Complete response drafts matching your team's tone and format, with inline links to relevant KB articles and step-by-step resolution instructions.
Key technology choices and the reasoning behind each decision.
Gemini 2.5 Pro
AI / MLSelected for its 2M+ token context window — lets us include full conversation history, KB articles, and multimodal inputs in a single prompt without chunking. Claude's 200k limit required complex context management.
GPT-4o Vision
AI / MLChose GPT-4o specifically for screenshot analysis over Gemini Vision due to its superior UI element recognition. In testing, GPT-4o correctly identified broken form elements 23% more often than alternatives.
Pinecone
DataSelected over pgvector for the KB search because of Pinecone's managed scaling and metadata filtering. With 10k+ articles updated daily, Pinecone's real-time index updates eliminated manual HNSW rebuilds.
PydanticAI Schemas
AI / MLUsed PydanticAI to enforce structured output schemas for urgency classification, resolution steps, and confidence scores. Eliminates the "hope the LLM formats it right" problem entirely.
Multimodal fusion pipeline with parallel processing and structured diagnostic output.
Input Processing
Screenshot → GPT-4o Vision | Voice → Whisper v3 | Text → direct pass-through (parallel)
Context Fusion
Modality outputs merged into unified diagnostic context with entity extraction
KB Retrieval
Hybrid search across Pinecone (past resolutions + KB articles) → MMR reranking
Diagnosis
Gemini 2.5 Pro analyzes fused context + KB results → P0-P3 classification + root cause
Response Draft
PydanticAI structures response with resolution steps, KB links, and confidence score
Key technical challenges I faced and how I solved them.
Multimodal Context Alignment
Screenshots, voice, and text often described the same issue from different angles. The AI would treat them as three separate problems, generating contradictory diagnoses 28% of the time.
Built a context alignment layer that extracts entities (error codes, UI elements, user actions) from each modality and creates a unified problem graph before sending to the reasoning LLM. Conflicting signals are flagged explicitly.
Contradictory diagnosis rate dropped from 28% to 3%. Multi-modal tickets now receive more accurate responses than single-modality ones.
Response Tone Consistency
AI-drafted responses didn't match the support team's established tone — too formal for some teams, too casual for enterprise clients. Agents were spending time rewriting every draft.
Implemented a few-shot tone calibration system. During onboarding, teams provide 10 example responses. The system extracts tone vectors and includes them in the generation prompt, adapting formality, emoji usage, and sentence structure.
Agent acceptance rate for AI drafts increased from 34% to 78%. Average edit distance dropped by 65%.
Interested in working with TwilightCore?
We build production systems like this for teams and founders who value quality engineering.