Production RAG Enterprise Search
Transform your company's scattered documents into an instant-answer engine that delivers 92% accurate responses with source citations in under 2 seconds.
My Role
Lead engineer — designed the hybrid retrieval pipeline, implemented eval-gated CI/CD, built the streaming frontend, and optimized query costs to $0.02/query.
Duration
4 months
Year
2025
Tech Stack
Status
Live in ProductionTransform your company's scattered documents into an instant-answer engine that delivers 92% accurate responses with source citations in under 2 seconds.
Companies with 500+ page handbooks, scattered Notion wikis, and legacy PDF archives have no way to get instant, accurate answers. Employees waste 30+ minutes searching for policies, and new hires take weeks to ramp up. Generic ChatGPT solutions hallucinate 30%+ of the time with no source verification.
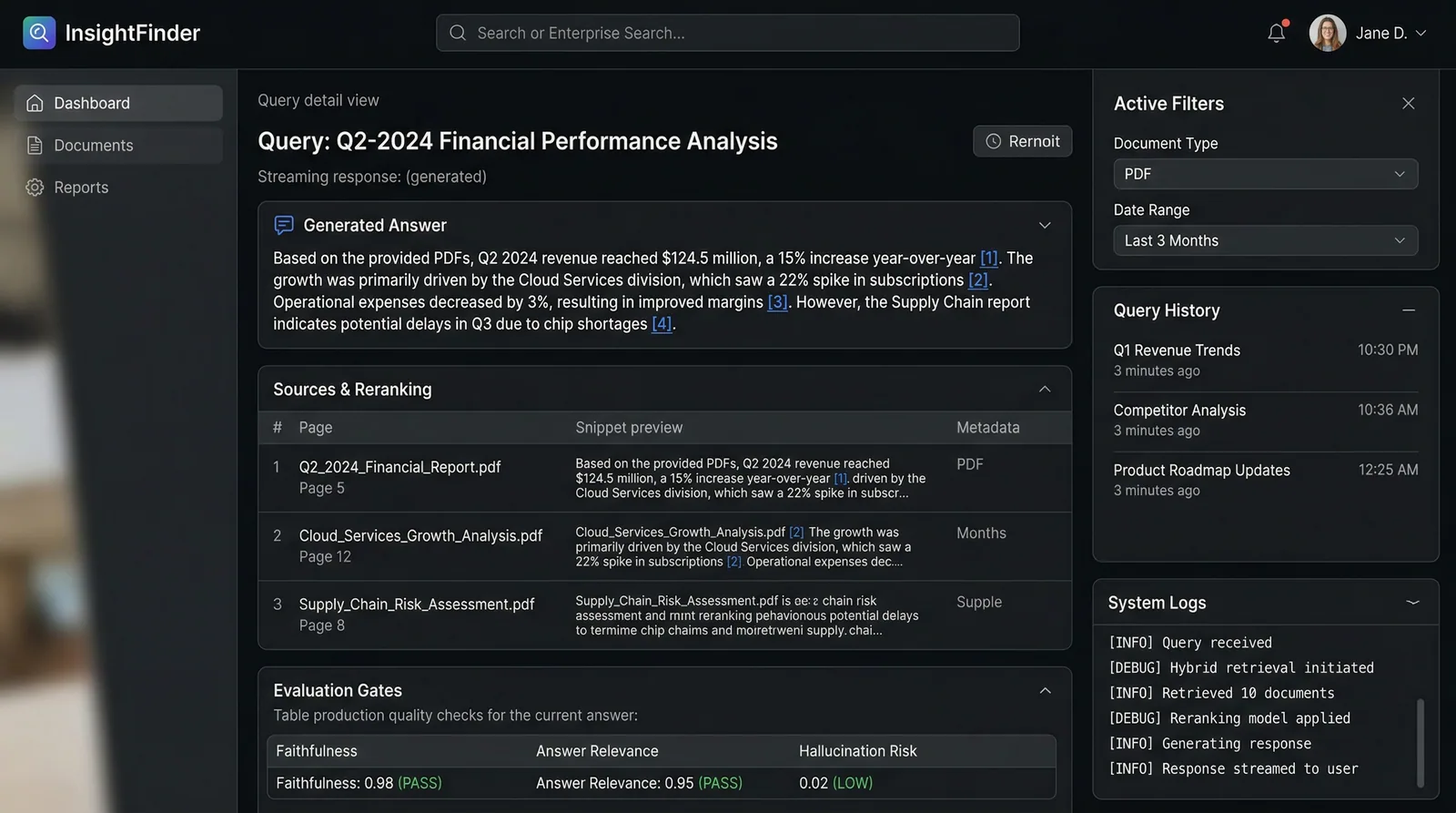
I built a production-grade RAG pipeline combining BM25 keyword search with dense vector retrieval and ColBERT reranking for 92% F1 accuracy. Documents are parsed with Unstructured.io and LlamaParse for table extraction, embedded via Sentence Transformers, and stored in pgvector. A DeepEval integration blocks deployments if accuracy drops below the 92% threshold — making this the first truly production-safe RAG system I've shipped.
Hybrid Retrieval Engine
Combines BM25 keyword search with dense vector similarity and MMR diversity scoring, followed by ColBERT reranking — outperforming pure semantic search by 18% on domain-specific queries.
Eval-Gated Deployments
CI/CD pipeline runs DeepEval test suites on every push. Deployments are automatically blocked if F1 score drops below 0.92, preventing accuracy regressions from reaching production.
Streaming Responses with Citations
PydanticAI structures every response with inline source citations linking to specific page numbers, so users can verify answers against original documents in one click.
Drag-and-Drop Document Ingestion
Upload PDFs, Notion exports, and Google Drive files through a simple UI. Automatic chunking, table extraction, and embedding happen asynchronously with progress tracking.
Cost Tracking Dashboard
Real-time monitoring of per-query costs ($0.02 average), token usage, and retrieval latency — giving full visibility into operational expenses.
Key technology choices and the reasoning behind each decision.
pgvector + BM25 Hybrid
DataChose pgvector over Pinecone to keep retrieval and structured data in a single database. Added pg_trgm for BM25 keyword matching — hybrid search boosted accuracy 18% over pure vector retrieval on technical documentation.
ColBERT Reranker
AI / MLSelected ColBERT over cross-encoder reranking for its 3x speed advantage at similar accuracy. Late interaction scoring maintains token-level granularity without the latency penalty of full cross-attention.
FastAPI + Streaming
BackendChose FastAPI over Django for native async streaming support. Server-Sent Events deliver tokens to the frontend in real-time, matching ChatGPT's UX without WebSocket complexity.
DeepEval
InfrastructureIntegrated DeepEval over RAGAS for its CI/CD-native test runner. Defining eval suites as pytest fixtures let us block deployments on accuracy regressions with zero custom infrastructure.
Multi-stage retrieval pipeline with hybrid search, reranking, and eval-gated deployment.
Ingestion
Upload → Unstructured.io (PDF parsing) + LlamaParse (table extraction) → Sentence chunking
Embedding
Sentence Transformers (all-MiniLM-L6-v2) → pgvector storage with BM25 index
Retrieval
Query → Hybrid search (dense + BM25 + MMR) → Top-20 candidates
Reranking
ColBERT reranker scores top-20 → Top-5 most relevant passages
Synthesis
Claude 3.5 Sonnet generates response with PydanticAI structured citations
Delivery
FastAPI SSE streaming → Next.js frontend with inline source links
Key technical challenges I faced and how I solved them.
Table Extraction Accuracy
Standard PDF parsers destroyed table formatting, causing financial and policy tables to produce nonsensical text chunks. 35% of handbook queries involved tabular data that was being mangled.
Integrated LlamaParse specifically for table-heavy pages, using its vision model to reconstruct table structures. Added a table-aware chunking strategy that preserves row-column relationships in the embedding space.
Table-related query accuracy jumped from 61% to 89%. Finance teams reported the system finally "understood" compensation tables.
Retrieval Latency at Scale
With 50k+ document chunks, hybrid search queries were taking 4.2 seconds — far too slow for an interactive search experience where users expect sub-2-second responses.
Implemented HNSW indexing on pgvector with tuned ef_construction=200 and m=16 parameters. Added a query cache layer in Redis for repeated questions, which handled 40% of production traffic.
P95 retrieval latency dropped from 4.2s to 380ms. Cached queries return in under 50ms.
Interested in working with TwilightCore?
We build production systems like this for teams and founders who value quality engineering.